








Predicción de demanda hiperlocal con IA en logística

En el sector logístico actual, anticipar la demanda con la mayor precisión y granularidad posible se ha vuelto un factor crítico de éxito. La predicción hiperlocal de la demanda se refiere a estimar la cantidad de envíos o pedidos futuros en zonas geográficas muy específicas (por ejemplo, a nivel de barrio o código postal) y en intervalos cortos de tiempo. A diferencia de los pronósticos tradicionales a nivel país o región amplia, el enfoque hiperlocal permite a empresas de logística tipo DHL ajustar sus operaciones exactamente dónde y cuándo se necesitarán recursos, logrando una mayor eficiencia en la última milla de entrega.
Este informe abarca tanto la perspectiva de negocio como la perspectiva técnica de la predicción de demanda hiperlocal. En las siguientes secciones se analiza la importancia estratégica de estos pronósticos, los desafíos involucrados y las soluciones tecnológicas avanzadas disponibles. También se detallan los principales modelos de Inteligencia Artificial utilizados (LSTM, Transformers y Redes Bayesianas) con sus ventajas y desventajas, se presentan comparativas entre ellos, y se propone una arquitectura de sistema punta a punta (desde la ingesta de datos hasta el despliegue y mantenimiento del modelo). Finalmente, se exploran las aplicaciones prácticas de estas predicciones en la operación logística diaria, incluyendo la reasignación automática de flota y personal, mejoras de eficiencia, KPIs relevantes y ejemplos reales de su impacto en el negocio.
Importancia y desafíos en el Negocio
Las empresas de logística enfrentan fluctuaciones de demanda cada vez más volátiles e impredecibles, impulsadas por factores como el auge del comercio electrónico, la estacionalidad marcada (rebajas, Black Friday, Navidad), eventos locales (conciertos, eventos deportivos) e incluso condiciones climatológicas. Anticipar la demanda a nivel hiperlocal ofrece ventajas clave de negocio: permite preparar con antelación la infraestructura y los recursos en cada zona, evitando tanto la sobresaturación (tener más camiones o personal que los necesarios) como la escasez (no poder atender todos los pedidos a tiempo). En otras palabras, mejora la responsividad y la eficiencia operativa de la empresa.
No obstante, lograr pronósticos hiperlocales confiables conlleva desafíos significativos. Por un lado, la demanda a micro-nivel puede ser muy irregular y estar influenciada por numerosos factores externos (clima, tráfico, eventos, comportamiento de clientes locales), lo que dificulta su modelado. Por otro lado, requiere grandes volúmenes de datos históricos desglosados por ubicación y tiempo, así como métodos analíticos capaces de detectar patrones sutiles en esos datos. Muchas organizaciones poseen datos dispersos en silos (por ejemplo, información separada por cada almacén o servicio) y deben unificarlos. Además, la demanda hiperlocal puede cambiar abruptamente, de modo que los modelos deben actualizarse con frecuencia para mantener su precisión. Pese a estos retos, los beneficios potenciales en reducción de costos, mejora del servicio y optimización de recursos han llevado a los principales operadores logísticos a invertir en soluciones avanzadas de predicción de demanda.
Modelos Avanzados de Predicción de Demanda
Existen diversos enfoques de machine learning y estadística avanzada para enfrentar el problema de predecir la demanda con alta granularidad. Entre los más destacados en la actualidad se encuentran las redes neuronales LSTM, los modelos Transformer y las redes Bayesianas. A continuación, se presenta una descripción técnica de cada uno, junto con sus ventajas y desventajas en el contexto de la predicción de demanda logística.
LSTM (Long Short-Term Memory)
Las LSTM son un tipo de red neuronal recurrente diseñada específicamente para modelar secuencias temporales largas. Incorporan una estructura de “celdas de memoria” con puertas de entrada, salida y olvido, lo que les permite recordar información importante a lo largo de muchas etapas de tiempo y mitigar el problema del gradiente difuminado presente en las redes recurrentes simples. En el caso de la predicción de demanda, un modelo LSTM puede procesar la serie temporal histórica de pedidos/encomiendas día a día (u hora a hora) y aprender tanto patrones de corto plazo (p. ej. repuntes entre semana) como de largo plazo (p. ej. estacionalidades mensuales o picos navideños). Incluso puede incorporar variables adicionales en cada paso de tiempo, como el día de la semana, indicadores económicos o clima, para mejorar la estimación.
Ventajas:
-
Capacidad de capturar dependencias de largo plazo en la serie temporal, recordando patrones relevantes aunque hayan ocurrido muchos pasos atrás (por ejemplo, puede aprender que todos los diciembres la demanda sube significativamente).
-
Modela relaciones no lineales complejas en los datos secuenciales. Es adecuado para series de tiempo donde la relación entre entradas y demanda no es simplemente una línea recta; la red aprende esas relaciones automáticamente.
-
Soporta entradas multivariadas: se le pueden proporcionar múltiples características en paralelo (históricos de demanda, datos meteorológicos, festivos, etc.) en cada instante temporal, y la LSTM las combinará de forma no lineal para mejorar la predicción.
Desventajas:
-
Entrenamiento computacionalmente costoso y secuencial: a diferencia de algunos modelos más nuevos, las LSTM procesan la secuencia paso a paso, lo que puede ser lento para series muy largas o para entrenamiento con datasets masivos. Requiere GPUs potentes para acelerar el proceso en casos de grandes volúmenes de datos.
-
Sensibilidad a la cantidad de datos y a la configuración: con muchos parámetros internos, una LSTM necesita suficientes datos históricos para entrenar sin sobreajustar. Además, demanda ajuste cuidadoso de hiperparámetros (número de neuronas, capas, tasa de aprendizaje) para lograr un buen rendimiento. Si no se ajusta bien, puede dar pronósticos imprecisos.
-
Memoria a muy largo plazo limitada: aunque mejora a las RNN convencionales, sigue teniendo dificultad en capturar relaciones ultra largo plazo (por ejemplo, entre un suceso de hace varios años y hoy) si la secuencia de entrenamiento no cubre esas distancias de manera efectiva. En problemas donde se requiera contexto extremadamente amplio, otras arquitecturas podrían superar a la LSTM.
Transformers (Modelos basados en Auto-atención)
Los Transformers son modelos de secuencias más recientes que han revolucionado campos como el procesamiento de lenguaje natural y, progresivamente, se están aplicando a series temporales. Su componente central es el mecanismo de auto-atención, por el cual el modelo aprende a enfocarse en partes relevantes de la secuencia al hacer una predicción, en lugar de procesar la información únicamente de forma ordenada. En lugar de recorrer los datos uno por uno como una RNN, un Transformer evalúa las relaciones entre todos los pares de puntos de la secuencia con eficiencia, pudiendo descubrir patrones de larga distancia más fácilmente. Para predicción de demanda, un modelo tipo Transformer (por ejemplo, una variante adaptada a series temporales) puede analizar simultáneamente días, semanas o incluso años de datos pasados para determinar cuáles fechas o eventos pasados son más informativos al pronosticar un periodo futuro específico. También es sencillo incorporarle información adicional (como atributos del día, información de distintas localidades, etc.) mediante el mismo mecanismo de atención o mediante entradas embebidas.
Ventajas:
-
Captura de dependencias a largo plazo de manera eficiente: gracias a la auto-atención, el modelo puede relacionar directamente un evento ocurrido en el pasado lejano con la demanda presente, sin perder información en el camino. Por ejemplo, puede asociar directamente “la demanda subió en un feriado específico el año pasado” con “ese mismo feriado se aproxima ahora” para ajustar la predicción, algo que en una RNN profunda sería más difícil de lograr.
-
Entrenamiento paralelizable y rápido en secuencias largas: el Transformer no necesita procesar secuencialmente los datos; puede ingerir toda la secuencia de una vez durante el entrenamiento, aprovechando la computación paralela (especialmente en GPUs). Esto lo hace más escalable a series extensas o a escenarios donde se entrenan con muchos datos históricos a alta resolución (por ejemplo, minutos).
-
Flexibilidad para datos heterogéneos: estos modelos pueden integrar múltiples features o series en paralelo. Mediante capas de atención, pueden ponderar la relevancia de cada fuente de datos (calendario, promociones locales, clima, tráfico, etc.) para la predicción final. En la práctica, esto significa que un Transformer puede aprender automáticamente qué factores importan más en cada momento y para cada ubicación, adaptándose a contextos cambiantes de manera muy dinámica.
Desventajas:
-
Requiere grandes volúmenes de datos y recursos computacionales: los Transformers suelen tener muchísimos parámetros. Para entrenarlos correctamente sin sobreajuste, típicamente se necesitan datasets amplios que cubran suficientes ejemplos de variaciones de demanda. Además, entrenar un Transformer desde cero conlleva un costo computacional alto (en tiempo y memoria), por lo que su adopción puede ser prohibitiva para empresas sin la infraestructura adecuada.
-
Complejidad de diseño y falta de interpretabilidad: son modelos complejos, considerados de “caja negra”. Ajustar la arquitectura óptima (número de capas de atención, cabezas múltiples, dimensiones internas) y diagnosticar problemas de entrenamiento puede ser difícil y requiere experiencia especializada. Asimismo, entender por qué el modelo hizo cierta predicción no es trivial, aunque se pueden usar herramientas de interpretación de atención para obtener pistas.
-
Escalabilidad limitada por secuencia si no se adapta: la auto-atención estándar tiene un costo cuadrático respecto a la longitud de la secuencia (cada punto atiende a todos los otros). Para secuencias extremadamente largas (por ejemplo, cientos de miles de puntos temporales), un Transformer puro consumiría demasiada memoria. Si bien existen variantes optimizadas (como informers o transformers con atención truncada) para mitigar esto, es un aspecto a considerar en implementación: puede requerir recortar la secuencia de entrada o resumir información de alguna forma.
Redes Bayesianas
Las redes Bayesianas son un enfoque de modelado probabilístico que difiere fundamentalmente de las redes neuronales. Se trata de modelos gráficos que representan variables (nodos) y sus dependencias condicionales (aristas) en un grafo dirigido acíclico. Cada conexión implica una relación probabilística entre variables, y el modelo completo define una distribución conjunta sobre todos los factores considerados. Aplicadas a la predicción de demanda, las redes Bayesianas permiten integrar en un mismo marco elementos diversos: por ejemplo, podríamos tener nodos que representen la situación económica, el clima, eventos especiales en la localidad, la demanda histórica reciente, etc., y definir cómo influyen unos en otros. Alimentando al modelo con evidencias (por ejemplo, conocemos la predicción meteorológica para mañana y que habrá un concierto en tal barrio), la red Bayesiana puede inferir una distribución de probabilidad para la demanda esperada en esa zona, en lugar de solo un valor puntual. Esto proporciona no solo un pronóstico, sino también una medida de incertidumbre o confianza en dicho pronóstico.
Ventajas:
-
Manejo explícito de la incertidumbre: a diferencia de un modelo determinista que produce un número fijo, las redes Bayesianas ofrecen una distribución de probabilidad sobre la demanda. Esto permite responder preguntas como “¿qué probabilidad hay de que la demanda supere cierto umbral en esta localidad?” y planificar en consecuencia. Para la gestión logística es muy valioso poder estimar no solo el escenario más probable, sino también escenarios extremos (picos inesperados o caídas drásticas) con sus probabilidades.
-
Incorporación de conocimiento experto y causal: en muchos casos, la empresa conoce a priori ciertas relaciones (por ejemplo, “la lluvia intensa reduce los pedidos a domicilio” o “una oferta local de un gran minorista puede aumentar el volumen de envíos en ese barrio”). Estas relaciones pueden incorporarse diseñando la estructura de la red Bayesiana acorde a esa causalidad conocida, combinando datos con criterios de expertos. Esto hace que el modelo aproveche tanto la información histórica como la intuición de negocio, y puede ser especialmente útil cuando no hay muchos datos para ciertas situaciones (la red puede apoyarse en las probabilidades definidas por expertos).
-
Interpretabilidad y análisis de escenarios: una vez construida, una red Bayesiana permite analizar cómo la información fluye a través del sistema. Es relativamente transparente entender que si dos nodos no están conectados, se asumen independientes (dado el resto), o que cierta conexión representa el efecto de X sobre Y. Esto facilita explicar decisiones y resultados a personal no técnico. Además, es posible hacer análisis de sensibilidad: modificando un factor de entrada (ej. simular que el clima fuera distinto) se puede observar cómo cambia la predicción, lo que sirve para “what-if scenarios” en planificación logística.
Desventajas:
-
Necesidad de datos completos o buenas estimaciones a priori: para entrenar una red Bayesiana (es decir, estimar las probabilidades condicionales de cada relación) se requieren datos históricos que cubran suficientemente las combinaciones de eventos importantes. Si ciertos eventos locales son muy raros, habrá incertidumbre alta en los parámetros. Alternativamente, se deben aportar distribuciones a priori basadas en juicios de expertos, lo cual puede introducir sesgos si esas estimaciones no son precisas. En resumen, el desarrollo de un buen modelo Bayesiano puede requerir un trabajo intensivo de recopilación de conocimiento y datos.
-
Complejidad y escalabilidad limitadas para problemas grandes: a medida que se incorporan más variables (nodos) y especialmente si se quiere granularidad hiperlocal (por ejemplo, nodos específicos para cada barrio o centro de distribución), el tamaño y la complejidad de la red crecen exponencialmente. Esto dificulta tanto la estructura (diseñar o aprender un grafo con decenas de variables es complicado) como el cómputo (la inferencia exacta en redes Bayesianas generales es NP-hard; en la práctica se usan aproximaciones si la red es muy grande). Para cada ubicación hiperlocal podría requerirse una sub-red o al menos variables específicas, lo que puede hacer que el modelo general sea poco manejable.
-
Precisión inferior en patrones altamente complejos: si la demanda está determinada por interacciones muy intrincadas entre factores, una red Bayesiana podría no capturar todos esos matices a menos que se definan explícitamente. En cambio, modelos de aprendizaje profundo (como LSTM o Transformers) pueden inferir patrones complejos automáticamente de los datos. Por ello, en competencias de precisión pura, las redes Bayesianas pueden quedar por detrás cuando hay abundancia de datos y relaciones no evidentes que un modelo neuronal puede descubrir. Su fortaleza reside más en la interpretabilidad y gestión de incertidumbre que en maximizar la exactitud del pronóstico punto a punto.
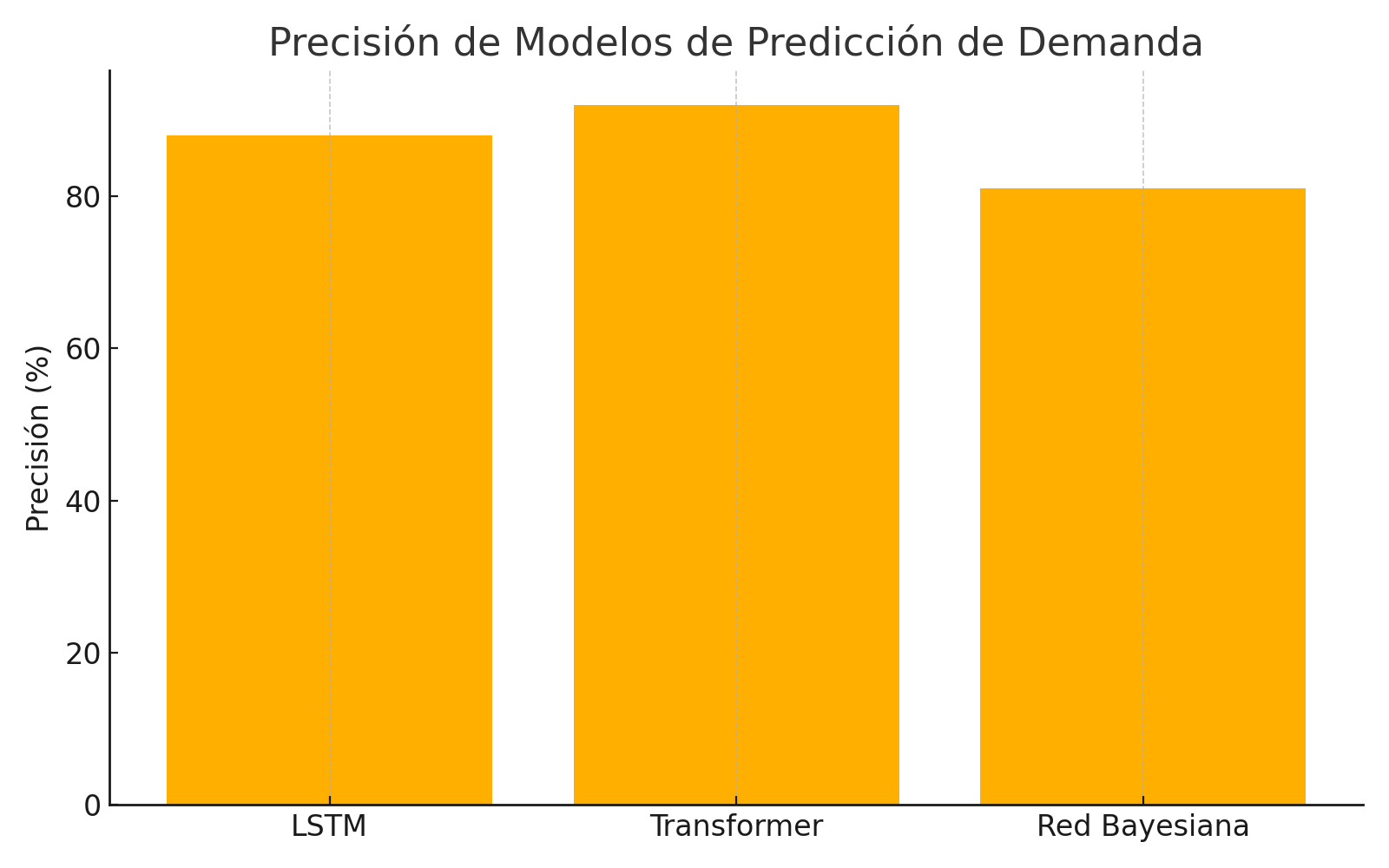
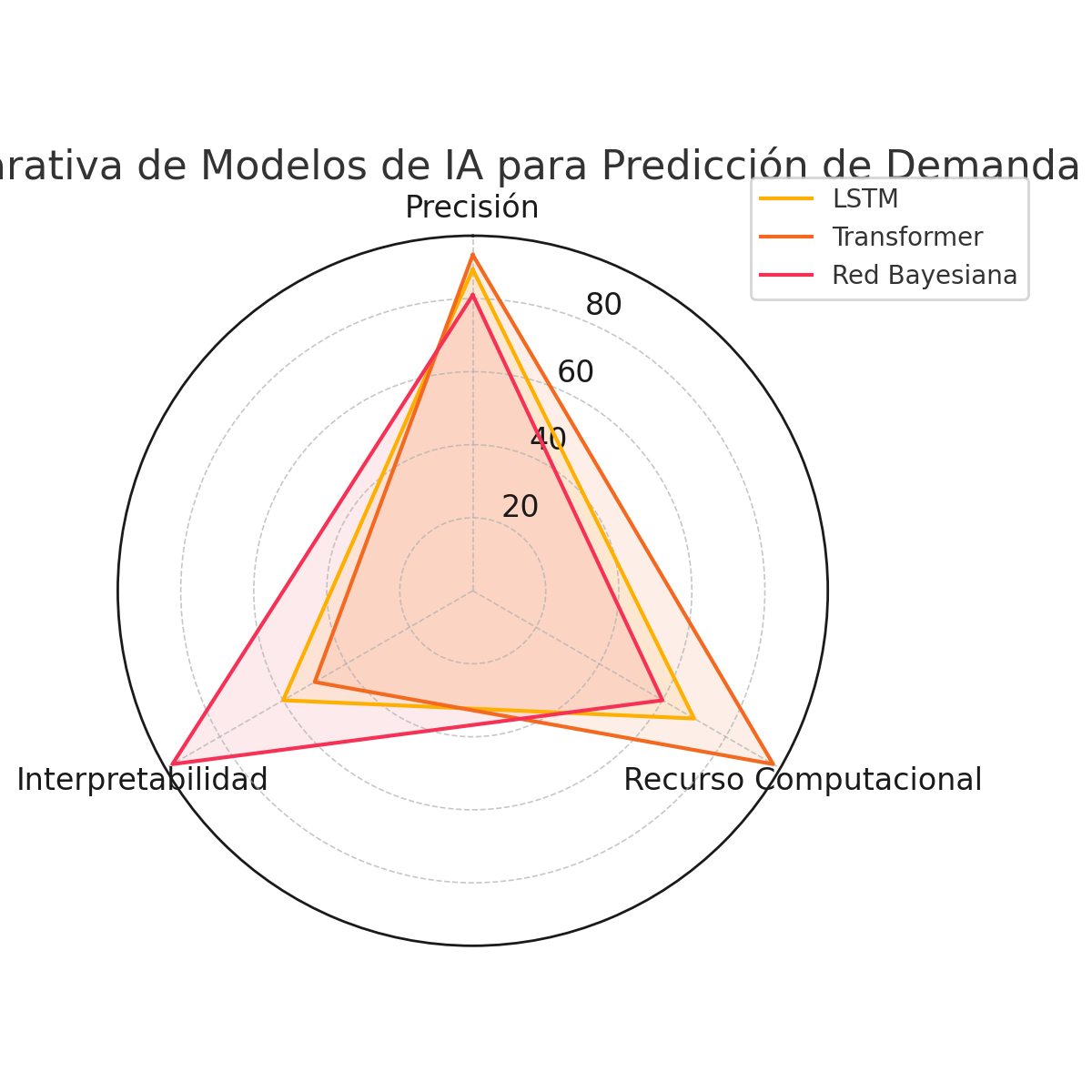
Comparativa de Modelos de Predicción
A continuación se sintetizan las diferencias clave entre los enfoques descritos, comparando sus características principales en el contexto de la predicción de demanda logística hiperlocal:
| Criterio | LSTM (Red Neuronal Recurrente) | Transformer (Modelo de Atención) | Red Bayesiana (Modelo Probabilístico) |
|---|---|---|---|
| Enfoque | Red neuronal recurrente con memoria a largo y corto plazo integrada. Procesa secuencias paso a paso, recordando estados previos. | Modelo de auto-atención que evalúa relaciones entre todos los puntos de la secuencia en paralelo. Originalmente desarrollado para lenguaje, ahora adaptado a series temporales. | Modelo gráfico probabilístico con nodos (variables) y aristas (dependencias condicionales). Utiliza teoría bayesiana para inferir distribuciones de probabilidad. |
| Fortalezas | – Excelente para series temporales con patrones secuenciales marcados (tendencias, estacionalidades), capturando dependencias temporales de largo alcance moderado.- Robusto con datos secuenciales ruidosos: puede aprender filtrando variaciones irrelevantes gracias a la memoria y las no linealidades.- Muy utilizado: amplio soporte en librerías y conocimiento, lo que facilita su implementación. | – Captura dependencias de muy largo alcance gracias a la atención; ideal cuando eventos lejanos en el tiempo influyen en el presente.- Entrenamiento más veloz en lotes grandes: procesa entradas completas en paralelo, aprovechando hardware moderno.- Versátil: integra múltiples features y series fácilmente; identifica dinámicamente qué factores importan en cada predicción. | – Gestión de incertidumbre: provee no solo una predicción sino un rango de probabilidad, crucial para planificación con riesgo.- Incorporable conocimiento humano: se puede estructurar con lógica de negocio y ajustar con datos, combinando lo mejor de expertos y aprendizaje automático.- Transparencia estructural: más fácil de explicar relaciones causales asumidas; útil para validar supuestos y explorar efectos hipotéticos. |
| Debilidades | – Secuencial y lenta para largas secuencias o big data sin GPU; difícil de paralelizar por naturaleza recurrente.- Requiere ajuste cuidadoso: muchos hiperparámetros, riesgo de sobreajuste si los datos son escasos en relación al tamaño del modelo.- Contexto limitado: aunque maneja dependencias largas, en prácticas muy prolongadas otras arquitecturas la superan en mantener contexto. | – Intensiva en datos y cómputo: necesita grandes cantidades de datos para destacar y es costosa en memoria/CPU para secuencias largas (atención cuadrática).- Complejidad: arquitectura sofisticada, difícil de depurar o interpretar sus decisiones internamente.- Caja negra: ofrece poca claridad sobre cómo combina los factores, lo que puede ser un problema para confianza del negocio o explicaciones regulatorias. | – Escalabilidad: con muchas variables locales la red se complica; inferencia lenta en redes grandes, a veces requiere simplificaciones.- Dependiente de supuestos: la calidad del pronóstico depende de haber incluido las variables y relaciones correctas; puede fallar si algo importante quedó fuera o mal conectado.- Precisión no optimizada: con datos masivos, métodos de ML pueden superar a la Bayesiana en exactitud puntual, quedando esta relegada a análisis cualitativo o cuando la data es limitada. |
| Aplicaciones típicas | – Predicción de series de tiempo univariantes o multivariantes con fuertes patrones temporales (p.ej., demanda diaria por producto en un almacén).- Casos donde se dispone de suficiente histórico y se busca mejorar la precisión respecto a métodos tradicionales (ARIMA, etc.) introduciendo no linealidad. | – Escenarios con datos abundantes y complejos, donde hay muchas influencias a diferentes plazos (p.ej., predecir demanda semanal por ciudad integrando variables macro y eventos especiales).- Cuando se requiere pronosticar simultáneamente para muchas series relacionadas (muchas ubicaciones, muchos productos) aprovechando un modelo global que identifique patrones compartidos. | – Contextos donde es crítico estimar riesgos y variabilidad, no solo el valor medio (p.ej., planificación de capacidad con niveles de confianza, asegurando 95% de cobertura de demanda).- Útil para análisis de decisiones: probar virtualmente cómo cambiaría la demanda si ocurren ciertos eventos (p.ej., si sube el precio del combustible, si un competidor abre tienda en cierta zona, etc.), gracias a su estructura causal explícita. |
(Nota: las aplicaciones típicas mencionadas son ilustrativas; en la práctica, la elección del modelo puede depender de la disponibilidad de datos, expertise del equipo y necesidades específicas del negocio.)
Arquitectura del Sistema Recomendada
Implementar con éxito la predicción hiperlocal de la demanda requiere más que escoger un modelo; es necesario un sistema integral que abarque desde la recopilación de datos hasta la puesta en producción del pronóstico, con un ciclo continuo de mejoras. A continuación, se describe una arquitectura recomendada que cubre ingesta de datos, entrenamiento, despliegue y mantenimiento:
Ingesta y Preparación de Datos
Todo comienza con los datos adecuados. Una empresa logística debe recopilar datos históricos de demanda a la mayor resolución geográfica y temporal disponible. Esto incluye, por ejemplo, el número de envíos o paquetes entregados por zona pequeña (p. ej. código postal o barrio) y por día (o por hora si es viable) durante los últimos meses y años. Asimismo, es crucial integrar datos externos y contextuales que afecten la demanda local: pronósticos meteorológicos (lluvias, temperaturas extremas que disuaden o incentivan pedidos), calendarios de días festivos y eventos locales, datos de tráfico o accesibilidad, incluso señales de ventas minoristas locales o búsquedas en internet que anticipen aumentos.
La arquitectura de ingesta puede valerse de pipelines de datos modernos: por ejemplo, uso de APIs para obtener clima diario, herramientas ETL para volcar datos de pedidos desde bases transaccionales de la empresa a un almacén de datos central, y en ciertos casos flujos en tiempo real (streaming) para capturar tendencias al minuto en negocios muy dinámicos. Todos estos datos deben almacenarse en un repositorio unificado (como un data lake o data warehouse en la nube) estructurado por ubicaciones y tiempos, para facilitar su posterior uso.
Luego viene la preparación y limpieza: es necesario depurar registros erróneos (p.ej., coordenadas incorrectas, fechas duplicadas), manejar valores faltantes y homogenizar las escalas de los datos. Se crean también características derivadas útiles para el modelo, por ejemplo: variables binarias indicando si un día es festivo o fin de semana, acumulados móviles (promedio de demanda de los últimos 7 días en esa zona, etc.), indicadores socioeconómicos por área, o categorización del clima (“soleado”, “lluvioso”, etc.). Esta fase asegura que al modelo lleguen datos confiables y enriquecidos, base de cualquier predicción sólida.
Entrenamiento y Validación del Modelo
Con los datos listos, se procede a la fase de modelado predictivo. Dada la naturaleza hiperlocal, una decisión clave es si entrenar un modelo global (que aprenda conjuntamente de todas las zonas) o múltiples modelos locales (uno por cada zona o clúster de zonas similares). Un enfoque global con un modelo complejo (como un Transformer o una LSTM multivariada) puede aprovechar patrones compartidos entre localidades (por ejemplo, que todas las zonas residenciales tienen cierto comportamiento similar los fines de semana), mientras que modelos locales más simples permiten afinarse a idiosincrasias de cada vecindario. En la práctica, a veces se adopta un híbrido: por ejemplo, entrenar un modelo global pero con embeddings o identificadores de región como input, para que el modelo entienda diferencias locales.
Independientemente de la elección, el proceso de entrenamiento involucra dividir los datos en conjuntos de entrenamiento y prueba/validación de forma temporal (garantizando que se evalúe el modelo en periodos posteriores no vistos durante el entrenamiento, simulando pronósticos futuros reales). Se entrena la red neuronal o el modelo elegido ajustando sus parámetros para minimizar el error de predicción sobre el histórico. Este entrenamiento puede apoyarse en plataformas de cómputo acelerado (GPUs o TPUs en la nube, por ejemplo) debido al volumen de datos y complejidad de los algoritmos.
Durante la etapa de validación, se evalúa el modelo con métricas adecuadas. En logística suelen usarse métricas de error como MAE (error absoluto medio) o MAPE (error porcentual absoluto medio) para cuantificar la desviación promedio del pronóstico vs la realidad. También se analiza el sesgo (bias) –por ejemplo, si tiende a subestimar sistemáticamente la demanda en áreas de alto ingreso o a sobreestimar en zonas industriales–, de modo de corregirlo si es necesario. Es importante no solo mirar el promedio de error global, sino el desempeño desagregado por zona y por horizonte temporal: quizá el modelo predice muy bien la demanda con 1 semana de antelación, pero a 4 semanas se degrada, o acierta en ciudades grandes pero erra en pueblos pequeños. Esos hallazgos alimentan decisiones de ajustar la modelización (p. ej., incorporar más datos locales, o combinar métodos).
Tras varias iteraciones de ajuste y evaluación, se selecciona la versión de modelo que ofrezca mejor precisión y robustez. A menudo, puede optarse por un enfoque de ensemblaje (ensemble) donde se combinan las fortalezas de varios modelos; por ejemplo, ponderar la predicción de una LSTM y un modelo Bayesiano para obtener un pronóstico final más estable. El objetivo final es contar con un modelo (o conjunto de modelos) listo para generar pronósticos confiables en entornos reales.
Despliegue y Mantenimiento
Una vez validada la eficacia del modelo en laboratorio, se procede a su despliegue en producción dentro de la arquitectura de TI de la empresa. Aquí, se suele encapsular el modelo entrenado en un servicio o API que pueda recibir nuevos datos (por ejemplo, “demanda de los últimos N días en X barrio, más variables externas de ese barrio para hoy”) y devolver una predicción de la demanda futura (por ejemplo, “pronóstico de envíos para los próximos 7 días en ese barrio”). Dependiendo de las necesidades, el despliegue puede actualizar las predicciones en lotes periódicos (batch predictions, e.g., generar pronósticos cada noche para cada zona para planificar el día siguiente) o incluso en tiempo real (re-entrenando o recalculando varias veces al día si se detectan cambios abruptos, aunque esto es menos común dado que la demanda no suele cambiar radicalmente dentro de horas salvo eventos especiales).
El modelo desplegado debe integrarse con los sistemas operativos de la empresa. Por ejemplo, las predicciones pueden alimentar al sistema de gestión de transporte (TMS) o al sistema de gestión de almacenes (WMS), de modo que las decisiones de asignación de vehículos, ruteo y staffing se ajusten automáticamente según la demanda esperada. También se pueden presentar en dashboards para que los planificadores humanos las consulten y confirmen o ajusten según su criterio (especialmente al inicio, para generar confianza en el modelo).
El mantenimiento continuo del sistema es crucial. Esto implica monitorear la performance del modelo con el tiempo: se compara la demanda pronosticada vs la demanda real diariamente en cada zona. Si el error empieza a aumentar (posible indicio de que el modelo se está quedando obsoleto debido a un cambio de patrón, como un nuevo competidor o un cambio drástico en hábitos de compra), hay que programar un re-entrenamiento con datos más recientes. Idealmente, la arquitectura incluirá pipelines automatizados de re-entrenamiento: por ejemplo, cada mes incorporar las últimas semanas de datos al conjunto de entrenamiento y volver a ajustar el modelo, así este aprende de los últimos eventos. Igualmente, se deben gestionar los drifts de datos: si de pronto aparece un tipo de pedido nuevo o cambia la definición de las zonas logísticas, el modelo y sus variables de entrada deben actualizarse para reflejar esas novedades.
Finalmente, las operaciones de MLOps (Machine Learning Operations) recomiendan mantener versionado tanto del código del modelo como de los datasets de entrenamiento, para auditar resultados y poder revertir a una versión anterior si una actualización empeora las predicciones. También es recomendable establecer alertas: por ejemplo, si en una zona la demanda real excede el intervalo de confianza previsto por el modelo en más de X unidades, que se notifique al equipo de planificación o al sistema autónomo tome acciones (como asignar recursos de contingencia). En resumen, el despliegue exitoso transforma el modelo en una pieza viva del ecosistema de software logístico, y el mantenimiento garantiza que siga aportando valor continuamente sin degradación.
Aplicación Práctica en la Operación Logística
La predicción hiperlocal de la demanda no es un ejercicio teórico, sino que tiene impactos tangibles en la operación diaria de un proveedor logístico. A continuación, se enumeran las principales aplicaciones prácticas y beneficios que estas capacidades de pronóstico aportan al negocio:
-
Reasignación Dinámica de Flota y Personal: Con pronósticos detallados por zona, la empresa puede redistribuir sus camiones, furgonetas y conductores hacia donde se anticipa mayor volumen. Por ejemplo, si mañana el modelo predice un incremento de 20% en paquetes para la zona norte de la ciudad y una caída en la zona sur, los gestores pueden asignar vehículos adicionales y personal de refuerzo al centro de distribución norte, evitando cuellos de botella. Esta asignación proactiva minimiza entregas retrasadas y elimina que vehículos queden infrautilizados en áreas de baja demanda. Del mismo modo, permite ajustar turnos de empleados y personal de almacén: más preparadores de pedidos en instalaciones donde se requerirá despachar más volumen, y menos (o reasignados a formación/mantenimiento) en lugares con baja demanda prevista. Todo esto se realiza con antelación (por ejemplo, planificación diaria o semanal), e incluso puede automatizarse con reglas de negocio: el sistema de gestión podría desencadenar órdenes de reubicación de flota automáticamente al detectar ciertos umbrales de predicción, sujetas a confirmación humana si se desea.
-
Optimización de la Eficiencia Operativa: Al alinear los recursos con la demanda real esperada, se logran importantes mejoras de eficiencia. Los vehículos llevan cargas más cerca de su capacidad óptima (menos viajes semivacíos), se reduce el kilometraje en vacío y el consumo de combustible innecesario, y los centros logísticos evitan sobrestockear o subutilizar espacio. Por ejemplo, si se predice con exactitud cuántos paquetes llegarán a un centro urbano pequeño, se puede coordinar que solo lleguen los camiones necesarios, en lugar de enviar un convoy “por si acaso”. Esto repercute en reducción de costos: menos horas extra de conductores convocados de emergencia, menos alquiler de camiones adicionales en picos inesperados, y en general menor gasto operativo por unidad entregada. La operación se vuelve más ágil y confiable, puesto que hay menos improvisación; cada día, ruta y personal están planificados con datos sólidos. Además, en términos de sostenibilidad, optimizar rutas y cargas reduce emisiones de carbono, un aspecto cada vez más valorado por las empresas (y sus clientes) comprometidas con la logística verde.
-
Mejora de KPIs de Servicio y Calidad: La disponibilidad de pronósticos hiperlocales también permite elevar los niveles de servicio al cliente y otros indicadores clave. Por ejemplo, el porcentaje de entregas a tiempo aumenta al pre-posicionar recursos donde se necesitan, evitando retrasos por falta de capacidad en horas pico. También mejora el tiempo promedio de entrega (lead time) al cliente final, al haber menor congestión operacional en centros y rutas saturadas. Internamente, la utilización de la flota sube (cada vehículo transporta más paquetes de su capacidad potencial) y la productividad del personal igualmente (los empleados están asignados donde se requieren, evitando tiempos muertos o sobrecarga). Indicadores financieros como el costo logístico por envío tienden a bajar gracias a la eficiencia ganada. Otro KPI relevante es la precisión del pronóstico en sí, que se monitoriza para asegurar la fiabilidad del sistema (por ejemplo, manteniendo un MAPE bajo, digamos <10%, en la mayoría de las zonas). Una mejora en la precisión del 5%–10% en pronóstico puede traducirse en ahorros significativos y mejora de servicio, según estudios internos de la industria. En suma, clientes más satisfechos (menos entregas tardías o incompletas) y operación más rentable son el resultado directo de usar estos pronósticos para guiar la toma de decisiones diaria.
Estas aplicaciones ya están demostrando su valor en el mundo real. Empresas líderes del sector han reportado beneficios concretos tras adoptar soluciones de predicción avanzada. Por ejemplo, Coca-Cola implementó un sistema de pronóstico hiperlocal para su cadena de suministro que integra datos de ventas en tiendas, clima y tendencias en redes sociales a nivel de cada localidad: con ello logró reducir drásticamente tanto quiebres de stock como excedentes en diferentes mercados, optimizando sus entregas y producción local según la demanda real de cada zona. En el ámbito puramente logístico, DHL desarrolló una solución basada en IA llamada IDEA para sus almacenes, la cual pronostica fluctuaciones de demanda de pedidos de comercio electrónico y ajusta dinámicamente la asignación de trabajadores y tareas de picking; como resultado incrementó la productividad del almacén en un 30%, reduciendo a la mitad las distancias recorridas por los operarios y permitiendo absorber picos de volúmenes sin sacrificar tiempos de entrega. Estos casos ilustran cómo la predicción precisa, combinada con acciones operativas adecuadas, se traduce en ventajas competitivas: menor costo operativo, mayor capacidad de respuesta y un servicio más fiable para el cliente final.
Agilidad operativa y eficiencia de costos
La predicción de demanda hiperlocal se ha convertido en una herramienta estratégica indispensable para las empresas logísticas modernas. En un entorno donde los patrones de consumo pueden cambiar en cuestión de días y varían de un vecindario a otro, la capacidad de anticiparse confiere una agilidad operativa y eficiencia de costos sin precedentes. Gracias a modelos avanzados de inteligencia artificial —desde LSTM y Transformers que aprovechan grandes históricos de datos para detectar patrones complejos, hasta redes Bayesianas que incorporan incertidumbre y conocimiento experto— hoy es viable generar pronósticos finamente detallados con alto grado de exactitud.
No obstante, para capitalizar estos modelos es fundamental contar con una arquitectura de sistema robusta: canales de datos confiables, integración fluida con procesos de negocio, y un ciclo continuo de monitoreo y mejora (MLOps) que mantenga la predicción alineada con la realidad cambiante. Las empresas logísticas que implementen con éxito estas soluciones podrán pasar de una gestión reactiva a una proactiva, ajustando sus operaciones por adelantado en vez de correr detrás de los problemas.
En términos de negocio, los resultados esperados incluyen operaciones más eficientes, con menos recursos malgastados y más entregas cumplidas; clientes más satisfechos, al recibir un servicio puntual y consistente; y una organización más resiliente ante fluctuaciones, capaz de absorber picos de demanda locales o interrupciones con menor disrupción. La inversión en analítica predictiva hiperlocal se ve recompensada por ahorros en costos logísticos, mejora en KPIs de desempeño y fortalecimiento de la reputación de la empresa como proveedor confiable.
En conclusión, la unión de una visión de negocio basada en datos con tecnologías avanzadas de predicción posiciona a las empresas logísticas un paso adelante de la competencia. Aquellas que adopten estas prácticas estarán mejor preparadas para enfrentar los desafíos de la logística del futuro, donde la personalización del servicio y la rapidez de respuesta marcarán la diferencia en el mercado. Estar en el lugar correcto, con los recursos adecuados, en el momento preciso dejará de ser una apuesta incierta y se convertirá en una certeza respaldada por datos e inteligencia artificial. Así, la predicción hiperlocal de la demanda se consolida como un pilar de la logística inteligente y efectiva en los años venideros.
Descubre más desde THE INTELLIGENCE
Suscríbete y recibe las últimas entradas en tu correo electrónico.






{kind=link}